%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Computer Vision

Camerabench
CameraBench is a model for analyzing camera motion in videos, aimed at understanding the motion patterns of cameras through video interpretation. Its main advantage lies in using generative visual language models for principle classification of camera motions and video-text retrieval. Compared with traditional Structure from Motion (SfM) and Simultaneous Localization and Mapping (SLAM) methods, this model shows significant advantages in capturing scene semantics. The model is open-source and suitable for use by researchers and developers, with more improved versions to be released later.
Research Tools
39.2K

Describe Anything
The Describe Anything model (DAM) can process specific regions of images or videos and generate detailed descriptions. Its main advantage lies in its ability to generate high-quality localized descriptions through simple markings (points, boxes, scribbles, or masks), greatly enhancing image understanding capabilities in the field of computer vision. The model was jointly developed by NVIDIA and several universities and is suitable for research, development, and practical applications.
Image Generation
39.5K

Easycontrol
EasyControl is a framework that provides efficient and flexible control for Diffusion Transformer (DiT), aiming to solve the efficiency bottlenecks and lack of model adaptability in the current DiT ecosystem. Its main advantages include: supporting multiple conditional combinations, improving generation flexibility and inference efficiency. This product is developed based on the latest research results and is suitable for use in image generation, style transfer, and other fields.
AI Model
38.4K
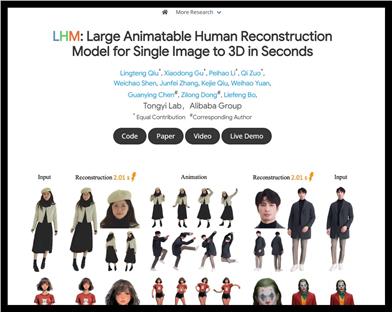
LHM
LHM (Large-scale Animatable Human Reconstruction Model) utilizes a multimodal transformer architecture for high-fidelity 3D head reconstruction, supporting the generation of animatable 3D human characters from a single image. The model can accurately preserve clothing geometry and texture, and is particularly excellent at restoring facial identity and details, making it suitable for application scenarios with high requirements for 3D reconstruction accuracy.
3D Modeling
58.5K
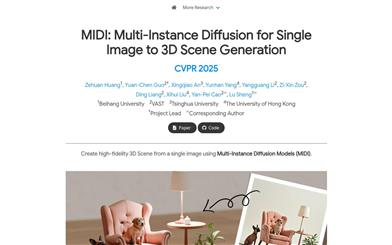
MIDI
MIDI is an innovative image-to-3D scene generation technology that utilizes a multi-instance diffusion model to directly generate multiple 3D instances with accurate spatial relationships from a single image. The core of this technology lies in its multi-instance attention mechanism, which effectively captures inter-object interactions and spatial consistency without complex multi-step processing. MIDI excels in image-to-scene generation, suitable for synthetic data, real-world scene data, and stylized scene images generated by text-to-image diffusion models. Its main advantages include efficiency, high fidelity, and strong generalization ability.
3D modeling
64.9K
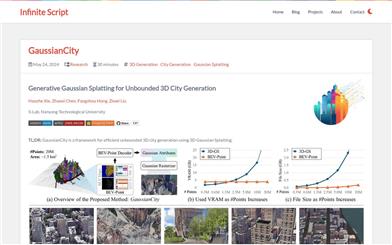
Gaussiancity
GaussianCity is a framework focused on efficiently generating boundless 3D cities, based on 3D Gaussian rendering technology. This technology, through compact 3D scene representation and a spatially aware Gaussian attribute decoder, solves the memory and computational bottlenecks encountered by traditional methods when generating large-scale city scenes. Its main advantage is the ability to quickly generate large-scale 3D cities in a single forward pass, significantly outperforming existing technologies. This product was developed by the S-Lab team at Nanyang Technological University, with the related paper published in CVPR 2025. The code and models have been open-sourced and are suitable for researchers and developers who need to efficiently generate 3D city environments.
3D Modeling
45.0K
Mlgym
MLGym is an open-source framework and benchmark developed by Meta's GenAI team and the UCSB NLP team for training and evaluating AI research agents. By offering diverse AI research tasks, it fosters the development of reinforcement learning algorithms and helps researchers train and evaluate models in real-world research scenarios. The framework supports various tasks, including computer vision, natural language processing, and reinforcement learning, aiming to provide a standardized testing platform for AI research.
Model Training and Deployment
52.2K
Pippo
Pippo, developed in collaboration between Meta Reality Labs and various universities, is a generative model capable of producing high-resolution, multi-view videos from a single ordinary photograph. Its core advantage lies in generating high-quality 1K resolution videos without any additional input (such as parameterized models or camera parameters). Based on a multi-view diffusion transformer architecture, it has broad application prospects in areas like virtual reality and film production. Pippo's code is open-source, but pre-trained weights are not included; users need to train the model themselves.
Video Production
104.6K

Videoworld
VideoWorld is a deep generative model focused on learning complex knowledge from pure visual inputs (unlabelled videos). It explores how to learn task rules, reasoning, and planning abilities using only visual information through autoregressive video generation techniques. The model's core advantage lies in its innovative Latent Dynamic Model (LDM), which efficiently represents multi-step visual transformations, significantly enhancing learning efficiency and knowledge acquisition capability. VideoWorld performs exceptionally well in video Go and robotic control tasks, showcasing its strong generalization ability and capacity to learn complex tasks. The research background of this model is inspired by the way biological entities learn knowledge through vision rather than language, aiming to pave new pathways for knowledge acquisition in artificial intelligence.
Video Production
62.1K
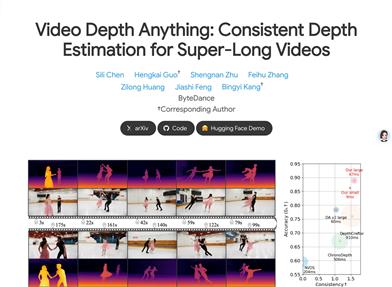
Video Depth Anything
Video Depth Anything is a deep learning-based video depth estimation model capable of providing high-quality and temporally consistent depth estimates for super-long videos. This technology is developed based on Depth Anything V2, boasting strong generalization capabilities and stability. Its primary advantages include the ability to estimate depth for any length of video, temporal consistency, and adaptability to open-world video. The model was developed by ByteDance's research team to address challenges in depth estimation for long videos, such as temporal consistency and adaptability in complex scenes. The code and demos for this model are currently available for researchers and developers.
Video Editing
57.4K
Vitpose
ViTPose is a series of human pose estimation models based on the Transformer architecture. It leverages the powerful feature extraction capabilities of Transformers to provide a simple yet effective baseline for human pose estimation tasks. The ViTPose models perform exceptionally well across various datasets, demonstrating high accuracy and efficiency. Maintained and updated by the community at the University of Sydney, the model offers various versions of different scales to meet diverse application needs. The ViTPose models are open-sourced on the Hugging Face platform, allowing users to easily download and deploy these models for human pose estimation research and application development.
AI Model
47.5K
Tryoffanyone
TryOffAnyone is a deep learning model designed to generate flat fabric images from photos of individuals wearing clothing. This model transforms images of clothed people into fabric flat-lays, which is significant for fashion design and virtual fitting applications. By leveraging deep learning technology, it achieves highly realistic fabric simulations, allowing users to intuitively preview how garments appear when worn. The main advantages of this model include realistic fabric simulation effects and a high degree of automation, which can reduce time and cost in the actual fitting process.
AI design tools
75.1K
Flagai
FlagAI, launched by the Beijing Academy of Artificial Intelligence, is a comprehensive and high-quality open-source project that integrates various mainstream large model algorithm technologies worldwide, as well as multiple large model parallel processing and training acceleration techniques. It supports efficient training and fine-tuning, aiming to lower the barriers to large model development and application while improving development efficiency. FlagAI covers several prominent models in various fields, such as language models like OPT and T5, vision models like ViT and Swin Transformer, and multi-modal models like CLIP. The Academy also continuously contributes the results of projects 'Wudao 2.0' and 'Wudao 3.0' to FlagAI. This project has been incorporated into the Linux Foundation, attracting global research talents for joint innovation and contribution.
Model Training and Deployment
47.7K
Video Analyzer
The video-analyzer is a video analysis tool that integrates Llama's 11B visual model and OpenAI's Whisper model. It captures key frames, inputs them into the visual model for detail extraction, and combines insights from each frame with available transcription to describe events occurring in the video. This tool represents a fusion of computer vision, audio transcription, and natural language processing, capable of generating detailed descriptions of video content. Its key advantages include complete local operation without the need for cloud services or API keys, intelligent key frame extraction from videos, high-quality audio transcription using OpenAI's Whisper, frame analysis with Ollama and Llama3.2 11B visual model, and the ability to generate natural language descriptions of video content.
Video Editing
107.4K
Megasam
MegaSaM is a system that allows for accurate, rapid, and robust estimation of camera parameters and depth maps from monocular videos of dynamic scenes. This system overcomes the limitations of traditional structure-from-motion and monocular SLAM techniques, which typically assume that the input videos primarily contain static scenes with significant parallax. MegaSaM can be extended to videos of complex dynamic scenes in the real world, including those with unknown fields of view and unconstrained camera paths, through carefully modified depth-visual SLAM frameworks. Extensive experiments on both synthetic and real videos demonstrate that MegaSaM is more accurate and robust in camera pose and depth estimation while being faster or comparable in runtime to previous and concurrent work.
3D Modeling
51.9K
NVIDIA Jetson Orin Nano Super Developer Kit
The NVIDIA Jetson Orin Nano Super Developer Kit is a compact generative AI supercomputer that offers superior performance at a lower price. It caters to a wide user base ranging from commercial AI developers to hobbyists and students, providing a 1.7x increase in generative AI inference performance, a performance boost to 67 INT8 TOPS, and an upgrade in memory bandwidth to 102GB/s. This product is ideal for developing retrieval-augmented generative LLM chatbots, building visual AI agents, or deploying AI-based robots.
Development and Tools
50.0K
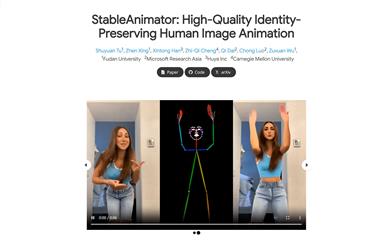
Stableanimator
StableAnimator is the first end-to-end identity-preserving video diffusion framework that synthesizes high-quality videos without the need for post-processing. This technology ensures identity consistency through conditional synthesis based on reference images and a series of poses. Its main advantage is that it does not rely on third-party tools, making it suitable for users who need high-quality portrait animations.
Video Production
67.3K

CHOIS
Controllable Human-Object Interaction Synthesis (CHOIS) is an advanced technology that simultaneously generates object and human movements based on linguistic descriptions, initial object and human states, and sparse object trajectory points. This technology is crucial for simulating realistic human behavior, particularly in scenarios that require precise hand-object contact and appropriate ground-supported interactions. CHOIS improves the matching between generated object movements and input object trajectory points by introducing object geometric loss as supplementary supervisory information and designing guiding terms during the training and sampling process of the diffusion model to enforce contact constraints, thereby ensuring the authenticity of the interactions.
3D Modeling
48.0K
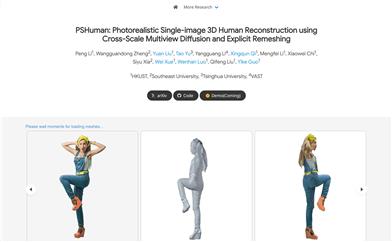
Pshuman
PSHuman is an innovative framework that utilizes multi-view diffusion models and explicit reconstruction techniques to reconstruct realistic 3D human models from a single image. Its significance lies in its ability to handle complex self-occlusion issues and avoid geometric distortions in the generated facial details. PSHuman achieves richly detailed new perspective generation while maintaining identity features by jointly modeling global body shapes and local facial characteristics with cross-scale diffusion models. Additionally, PSHuman enhances cross-view body shape consistency under different human postures using physical priors provided by parameterized models like SMPL-X. Key advantages of PSHuman include rich geometric details, high texture fidelity, and strong generalization capability.
3D Modeling
74.8K
Phantomy AI
Phantomy AI is an advanced tool that enhances user interaction and presentation through computer vision software, utilizing screen object detection and gesture recognition technologies. It allows intuitive gesture control of the screen without requiring additional hardware, providing users with a touch-free interaction method. Key advantages of Phantomy AI include precise screen object detection, gesture-based control, smooth slide navigation, an enhanced user experience, and a wide range of applications. The product was developed by AI engineer Almajd Ismail, who has a background in software and full-stack development. Specific information about pricing and positioning is not provided on the page.
Computer Vision
43.3K
Chinese Picks
DINO X
DINO-X is a large visual model centered on object perception, equipped with core capabilities like open-set detection, intelligent question answering, human pose recognition, object counting, and clothing color changing. It not only identifies known targets but also flexibly responds to unknown categories. With advanced algorithms, the model exhibits excellent adaptability and robustness, providing comprehensive solutions for complex visual data across various unpredictable challenges. The applications of DINO-X are extensive, including robotics, agriculture, retail, security monitoring, traffic management, manufacturing, smart homes, logistics and warehousing, and entertainment media. It is the flagship product of DeepDataSpace in the field of computer vision technology.
Object Detection
76.5K
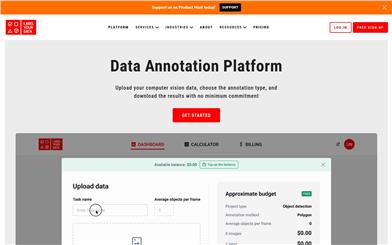
Data Annotation Platform
The Data Annotation Platform is an end-to-end solution that allows users to upload computer vision data, choose annotation types, and download results without any minimum commitment. It supports a variety of data annotation types, including bounding boxes, polygons, 3D cuboids, keypoints, semantic segmentation, instance segmentation, and panoptic segmentation, catering to AI project managers, machine learning engineers, AI startups, and research teams to tackle challenges encountered in the data annotation process. With features such as seamless execution, cost calculators, instruction generators, free tasks, API integration, and team access, the platform provides users with a straightforward, efficient, and cost-effective data annotation solution.
Computer Vision
52.2K
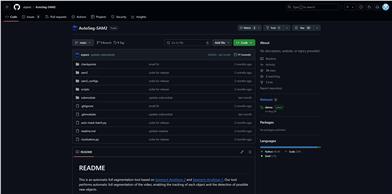
Autoseg SAM2
AutoSeg-SAM2 is an automatic full video segmentation tool based on Segment Anything 2 (SAM2) and Segment Anything 1 (SAM1). It enables tracking of each object in the video while detecting potential new objects. The tool's significance lies in providing static segmentation results and leveraging SAM2 to track these results, which is crucial for video content analysis, object detection, and video editing. This product was developed by zrporz, based on Facebook Research's SAM2 and zrporz's own SAM1. As an open-source project, it is available for free.
Object Tracking
50.8K
Turbolens
TurboLens is a comprehensive platform that integrates OCR, computer vision, and generative AI, capable of automating the rapid extraction of insights from unstructured images to streamline workflows. Background information indicates that TurboLens aims to extract customized insights from printed and handwritten documents through its innovative OCR technology and AI-driven translation and analysis suite. Additionally, TurboLens offers mathematical formula and table recognition features, converting images into actionable data while translating mathematical formulas into LaTeX and tables into Excel format. For pricing, TurboLens provides both free and paid plans to cater to different user needs.
Computer Vision
54.9K
Llama Mesh
LLaMA-Mesh is a technology that extends the capabilities of large language models (LLMs) pre-trained on text for generating 3D meshes. This technology leverages the spatial knowledge already embedded in LLMs, enabling conversational 3D generation and mesh understanding. The main advantage of LLaMA-Mesh lies in its ability to represent vertex coordinates and face definitions of 3D meshes as plain text, allowing direct integration with LLMs without the need to expand vocabularies. Key benefits include the capacity to generate 3D meshes from text prompts, on-demand generation of interleaved text and 3D mesh outputs, and the ability to understand and interpret 3D meshes. LLaMA-Mesh achieves mesh generation quality comparable to models trained from scratch while maintaining strong text generation performance.
Artificial Intelligence
55.8K

Countanything
CountAnything is a cutting-edge application that leverages state-of-the-art computer vision algorithms to achieve automated and precise object counting. It is suitable for various scenarios, including industrial, aquaculture, construction, pharmaceutical, and retail industries. The main advantages of this product are its high accuracy and efficiency, significantly enhancing the speed and accuracy of counting tasks. Currently, CountAnything is available for users outside mainland China and offers a free trial.
Object Counting
50.2K
NVIDIA AI Blueprint
NVIDIA AI Blueprint for Video Search and Summarization is a reference workflow based on NVIDIA NIM microservices and generative AI models, designed to build visual AI agents capable of understanding natural language prompts and executing visual question answering. These agents can be deployed in various scenarios, such as factories, warehouses, retail stores, airports, and traffic intersections, assisting operations teams in making better decisions based on rich insights generated from natural interactions.
AI Model
51.6K
Genxd
GenXD is a framework focused on 3D and 4D scene generation, utilizing common camera and object motion found in everyday life to jointly study general 3D and 4D generation. Due to a lack of large-scale 4D data in the community, GenXD initially proposes a data planning process to extract camera poses and object motion intensity from videos. Based on this process, GenXD introduces a large-scale real-world 4D scene dataset: CamVid-30K. By leveraging all 3D and 4D data, the GenXD framework can generate any 3D or 4D scene. It offers a multi-view-time module that separates camera and object motion, learning seamlessly from 3D and 4D data. Furthermore, GenXD employs masked latent conditions to support various conditional views. GenXD can generate videos that follow camera trajectories and consistent 3D views that can be enhanced to 3D representations. It has undergone extensive evaluation across various real-world and synthetic datasets, demonstrating its effectiveness and versatility in 3D and 4D generation compared to previous methods.
3D Modeling
47.7K
Tencent Hunyuan Large
Tencent-Hunyuan-Large is an industry-leading open-source large mixture-of-experts (MoE) model developed by Tencent, featuring a total of 389 billion parameters and 52 billion active parameters. The model has made significant advancements in natural language processing, computer vision, and scientific tasks, particularly excelling in handling long-context inputs and improving performance on long-context tasks. The open-source nature of this model aims to inspire innovative ideas among researchers and drive advancements and applications in AI technology.
AI Model
62.7K

Flex3d
Flex3D features a two-stage process that generates high-quality 3D assets from a single image or text prompt. This technology represents the latest advancements in the field of 3D reconstruction, significantly improving the efficiency and quality of 3D content generation. Flex3D is developed with support from Meta, and the team has a strong background in 3D reconstruction and computer vision.
AI 3D tools
62.4K
- 1
- 2
- 3
- 4
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.0K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.4K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
41.7K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
42.8K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.4K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.0K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.1K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M